
Scenario:
I was writing a blog on GSoC last week and I had to collect data from GSoC website to make few statistics I was interested in. The issue is, the data I wanted was scattered across many different pages (more than 200 different pages) and clicking each of these 200 pages and manually gathering data is a nightmare. So I resolved to the programmatic method of extracting visual data from websites: Screen Scraping. In this blog I will go through how I was able to collect the data I was interested in, by screen-scraping in R.
Understanding the problem:
‘2017 Organizations Archive’ page of GSoC website contains the details of 201 mentoring organizations in GSoC program. But this page has just the name of the organization and the link to the organization page. Actual data I need is in each of the organization pages that are linked from the main page.

‘Organizations Home Page’ with just organization name and link to ‘Organization Page’
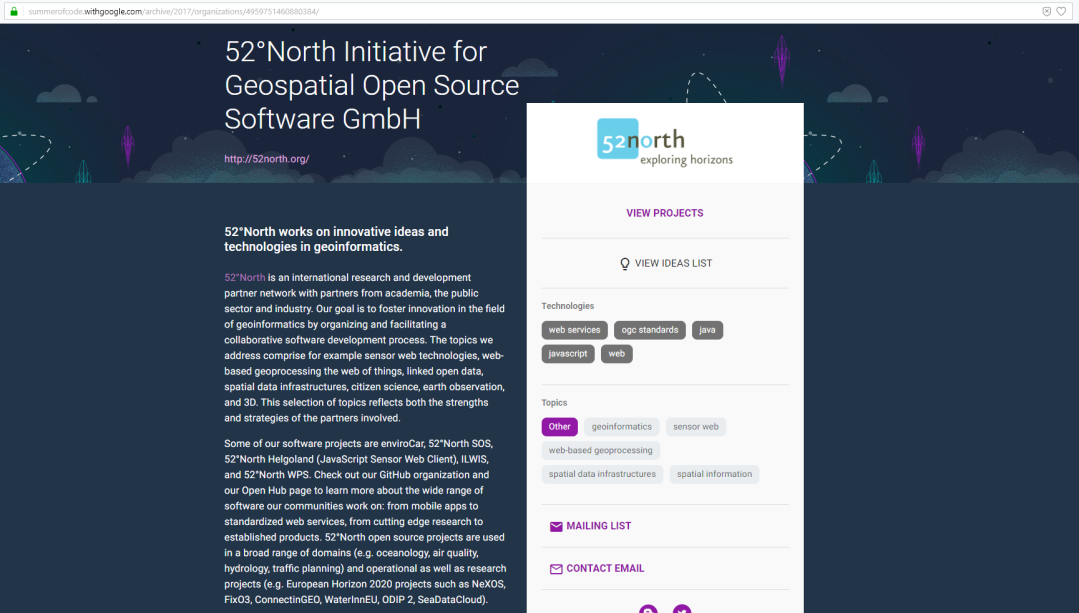
‘Organization Page’ of an organization with the data I need
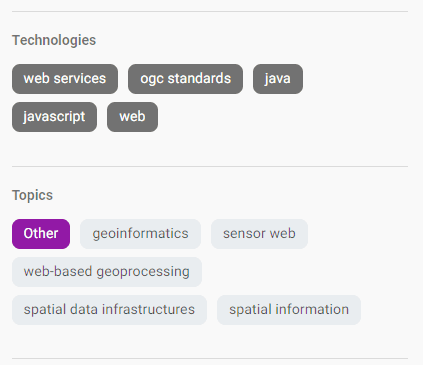
The data I needed in each ‘Organization Page’
Like this page I had to go to all 201 organization’s ‘Organization Page’ and gather the data.
So, first, I have to retrieve the links of all these organization pages and then I have to go to each of those links and extract the required data. Now that I understood what I have to retrieve, I started programming the scraper.
Identifying Elements:
Getting links of all 201 organization pages
First step of scraping is to identify how the elements in the page are structured and how the elements we are interested in are, identified.
In modern browsers, ‘Developer Options’ let us inspect HTML and other sources of the web pages. This is what we will be using to identify the elements in the page.
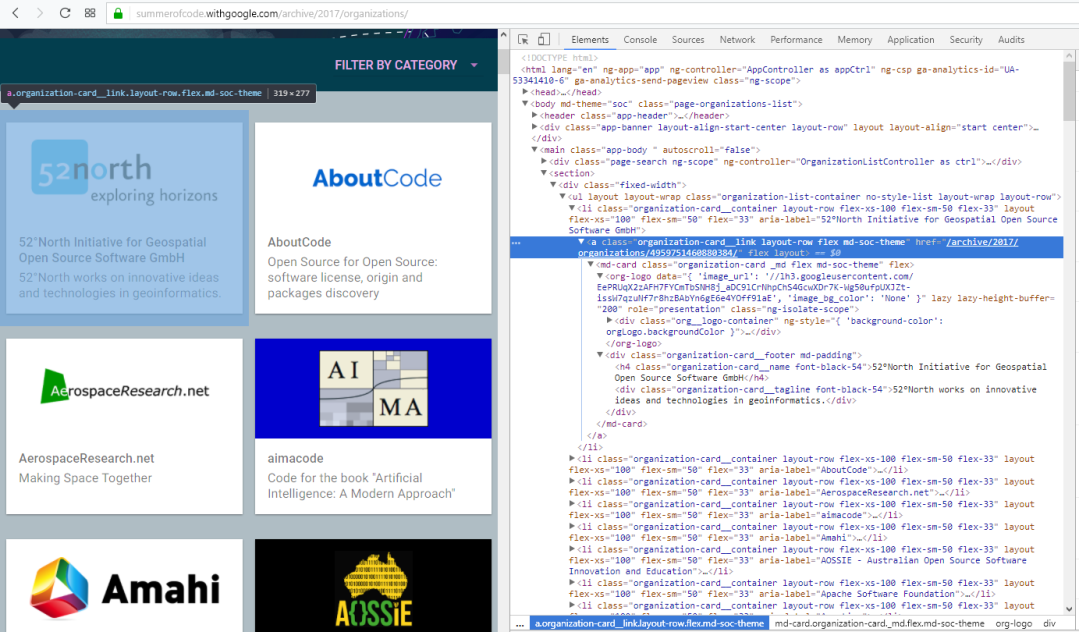
Here I have enabled the Developer Options and I have found a node which contains the link to an organization page. To find this you just have to click ‘Inspect Element’ button and hover over the element. The node is with the following HTML mark-up,
<a class="organization-card__link layout-row flex md-soc-theme"
href="/archive/2017/organizations/4959751460880384/" flex="" layout="">
<md-card class="organization-card _md flex md-soc-theme" flex="">
<org-logo data="{ 'image_url': '//lh3.googleusercontent.com/EePRUqX2zAFH7FYCmTbSNH8j_aDC9lCrNhpChS4GcwXDr7K-Wg50ufpUXJZt-issW7qzuNf7r8hzBAbYn6gE6e4YOff91aE', 'image_bg_color': 'None' }" lazy="" lazy-height-buffer="200" role="presentation" class="ng-isolate-scope">
...
</org-logo>
<!-- div class="organization-card__footer md-padding">
<!-- h4 class="organization-card__name font-black-54">
52°North Initiative for Geospatial Open Source
Software GmbH
</h4>
<!-- div class="organization-card__tagline font-black-54">
52°North works on innovative ideas and
technologies in geoinformatics.
</div>
</div>
</md-card>
</a>
Here, there are certain things to note. The links to the organization page is in the beginning <a> tag with attribute href.
<a class="organization-card__link layout-row flex md-soc-theme" href="/archive/2017/organizations/4959751460880384/" flex="" layout="">
So by just finding the values of href’s under the class organization-card__link will give us the links to the pages.
Secondly, the name of the organization and the tagline are in the h4 and div elements. But these are too generic as there are many h4 and div elements throughout the page. But once again the unique classes of these two elements (organization-card__name and organization-card__tagline) makes it easier to retrieve the values of the element.
<!-- h4 class="organization-card__name font-black-54">
52°North Initiative for Geospatial Open Source Software GmbH</h4>
<!-- div class="organization-card__tagline font-black-54">
52°North works on innovative ideas and technologies in geoinformatics.
</div>
Getting data from an Organization Page
Once we get link to an organization page, we have to get data from that page. Let’s inspect elements from such a page. 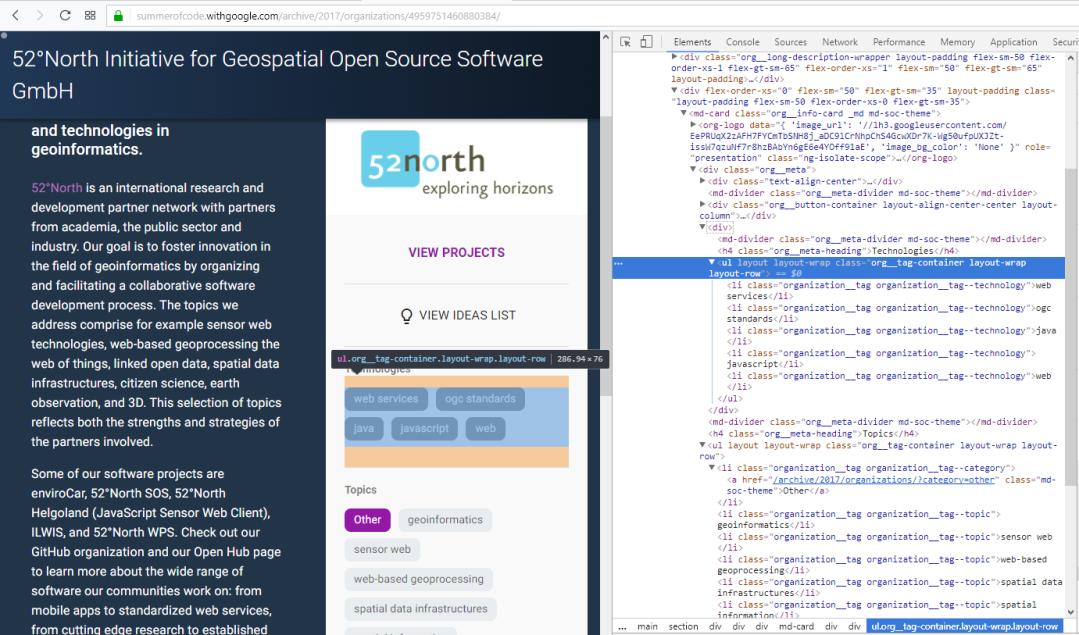 Here the data we need is in a list with the class organization__tag–technology.
Here the data we need is in a list with the class organization__tag–technology.
<!--div>
<md-divider class="org__meta-divider md-soc-theme"></md-divider>
<h4 class="org__meta-heading">Technologies</h4>
<ul layout="" layout-wrap="" class="org__tag-container layout-wrap layout-row">
<li class="organization__tag organization__tag--technology">web services</li>
<li class="organization__tag organization__tag--technology">ogc standards</li>
<li class="organization__tag organization__tag--technology">java</li>
<li class="organization__tag organization__tag--technology">javascript</li>
<li class="organization__tag organization__tag--technology">web</li>
</ul>
</div-->
Here all the tags are presented with the same class, which makes it easier for us to scrape.
Screen Scraping:
There are several R packages to do screen scraping. XML and XML2 can be used to parse HTML tags and get data in each node. But there are other packages which have been built as wrappers for these packages which offers much more functionalities with mush ease. Rvest is such a package and we will be using it to do screen scraping.
First, let’s download and load the package to R Environment.
# Setting up environment
install.packages("rvest")
library(rvest)
Then let’s create an XML Document from the website we are interested. Even HTML docs are normalized to XML Document in this step, which is fine.
# Creating XML Doc
doc <- read_html("https://summerofcode.withgoogle.com/archive/2017/organizations")
Now that we have HTML / XML representation of website, for the next step we will use the knowledge from ‘Identifying Elements’ part.
# Organization Names
organizations <- doc %>%
html_nodes(".organization-card__name") %>%
html_text()
Here, we are using piping functions feature of rvest with ‘%>%’. What this does is, it sends output of one function to the next function in the pipe as the first parameter. So the above code executed as follows,
doc is sent to the html_nodes function as first parameter,
html_nodes(doc, ".organization-card__name")
then the output of this function is sent to html_text function as the first parameter. So the above code is as same as,
html_text(html_nodes(doc, ".organization-card__name"))
Now, lets make sense of this set of code.
‘.organization-card__name‘ is the class of the h4 element which contains the name of the organization. There are 201 such elements in the homepage. We are selecting all those elements, with html_nodes(doc, “.organization-card__name”) function call. Then, with html_text() function call we are extracting texts in all those elements.
If we print the summary and content of the organization vector,
> summary(organizations) Length Class Mode 201 character character
> organizations[1:10] [1] "52°North Initiative for Geospatial Open Source Software GmbH" [2] "AboutCode" [3] "AerospaceResearch.net" [4] "aimacode" [5] "Amahi" [6] "AOSSIE - Australian Open Source Software Innovation and Education" [7] "Apache Software Foundation" [8] "Apertium" [9] "Apertus Association" [10] "appleseedhq"
voila, we get names of all the organizations in the page!
Now, lets see if we can get the URLs of each of the organization page linked from homepage.
# Organization Links
links <- doc %>%
html_nodes(".organization-card__link") %>%
html_attr('href')
Here, the only difference is, we are not using html_text() call. Reason is, the URL is a attribute of a element and not the value of a element. Thus, instead of html_text, we have to use html_attr(‘href’) function.
Let’s see what is returned for this function.
> links[1:3] [1] "/archive/2017/organizations/4959751460880384/" [2] "/archive/2017/organizations/6448304984424448/" [3] "/archive/2017/organizations/6713622831038464/"
Here, the pages are with the relative URLs of the homepage. It’s normal for servers to link pages with relative pages. But since we know the base URL, we can modify this and get the full URL.
links <- paste("https://summerofcode.withgoogle.com", links, sep = "")
> links[1:10] [1] "https://summerofcode.withgoogle.com/archive/2017/organizations/4959751460880384/" [2] "https://summerofcode.withgoogle.com/archive/2017/organizations/6448304984424448/" [3] "https://summerofcode.withgoogle.com/archive/2017/organizations/6713622831038464/" [4] "https://summerofcode.withgoogle.com/archive/2017/organizations/6119722806411264/" [5] "https://summerofcode.withgoogle.com/archive/2017/organizations/6673844588773376/" [6] "https://summerofcode.withgoogle.com/archive/2017/organizations/4780102642565120/" [7] "https://summerofcode.withgoogle.com/archive/2017/organizations/4633151007621120/" [8] "https://summerofcode.withgoogle.com/archive/2017/organizations/6618812501721088/" [9] "https://summerofcode.withgoogle.com/archive/2017/organizations/6354847569805312/" [10] "https://summerofcode.withgoogle.com/archive/2017/organizations/6110372931043328/"
Wheew! We got what we wanted!
Similarly, we can continue this and get all the data we need.
Remarks:
- Screen scraping is illegal in certain countries and against the Terms of several websites. So when you are about to screen scrape, make sure it is allowed to do so.
- To effectively use CSS selectors, refer https://cssselect.readthedocs.io/en/latest/
That’s all for this blog, May the Coding Gods be with You!!!

One thought on “Screen Scraping in R”